
Christopher Thierauf, Matthias Scheutz. IEEE Resilience Week 2025.
Can robots reason about what actions to take to better understand failure? I show a technique and demonstrate how this is possible.
Robots break, sensors get blocked, actuators jam, networks crash. Out in the real world, where things are messy and unpredictable, these failures are inevitable. But what happens after something goes wrong? Does the robot freeze up, wait for human intervention, or can it actually try to figure things out on its own?
That’s the question I tackled in this work: how to give robots the ability to self-debug. Instead of treating failure as the end of the operation, I wanted robots to treat it as the start of a reasoning process. This goes beyond typical fault discovery (read more at [1]) and extends it into an active process of self-experimentation.
Why Failures are Hard
Traditional fault detection systems in robotics usually work by comparing what should have happened to what did happen. If there’s a discrepancy, they throw an error. That’s fine as far as it goes, but it doesn’t actually help the robot do anything about the problem. At best, the robot hands over some diagnostic codes to a human technician.
What I wanted was different. Imagine your robot runs into trouble because its depth camera is blocked by debris. A conventional system would say: “I’m not moving toward my goal, something is wrong.” Then it would stop.
But what if the robot could go further? It could try some experiments:
- Compare odometry and IMU data to see whether the wheels are moving as expected (a)
- Wave its arm in front of its camera to see if the image changes (b)
- Block its own LIDAR with its gripper to check whether the LIDAR is still working (c)

These actions don’t fix the problem immediately, but they give the robot information. Information means it can form hypotheses about what’s broken and test them, narrowing down the possibilities until it has a clear picture of what’s wrong. As I show in this and later work, understanding the robot allows it to construct a plan to maybe even how to fix it (d).
The Fault Discovery Graph
To make this work, I introduced something called the Fault Discovery (FD) graph. Think of it like a map of how the robot’s hardware, software, and sensing are all causally connected.
- Observer nodes are at the bottom, representing things the robot can directly sense (wheel encoders, camera images, odometry readings).
- System nodes are in the middle, representing internal processes like the navigation stack or the gripper control loop.
- Problem nodes are the top. These represent possible failure states like “camera obstructed,” “LIDAR broken,” or “wheel jammed.”
When something doesn’t add up, the robot can trace through this graph. This allows it to actively reason about the failure: If this check failed, what could cause it? What tests could I perform to narrow it down?
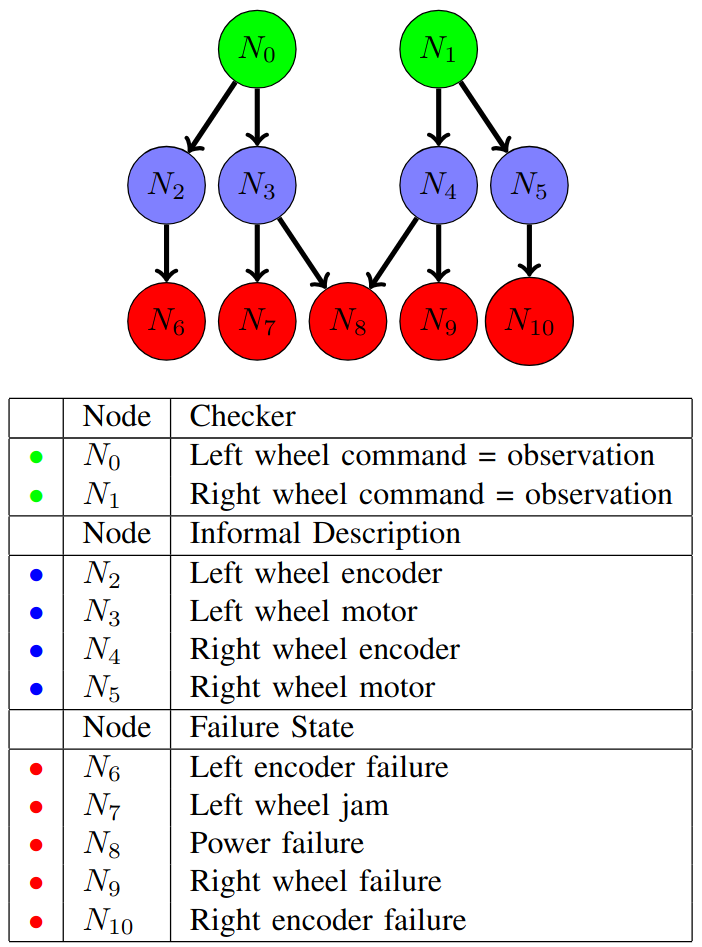
A simple graph for an imagined two-wheel robot, with encoders on each wheel capable of measuring the movement of that wheel.
Robots as Experimenters
The heart of the approach is to let robots behave like experimenters. When something breaks, the FD graph suggests actions that could produce new evidence. The robot tries them, updates its beliefs, and repeats.
This recursive loop of detect → hypothesize → test → refine lets the robot move beyond static fault detection and into active fault discovery. Sometimes the result is a real fix (like sweeping an obstruction off a sensor). Sometimes it’s a mitigation strategy (like reconfiguring to rely on a different sensor). And sometimes it ends with the robot admitting: “I can’t solve this, but here’s what I know, and I should call for help.”
Examples in Practice
I tested this system on a Fetch robot across a variety of scenarios:
- Resolvable failures: An obstructed camera that the robot could clear by sweeping its arm.
- Mitigable failures: A broken LIDAR that the robot couldn’t repair, but could work around by reconfiguring its navigation to use the depth camera (at reduced performance).
- Simultaneous failures: Cases where both a sensor and an actuator were affected, forcing the robot to debug in layers until both issues were handled.
- Non-mitigable failures: Total shutdowns where no action could help, but the robot could still diagnose and report the problem to a human.
In every case, the same underlying process worked: generate hypotheses, run tests, reason about what the evidence shows, and act accordingly.
Why This Matters
Robots in the wild won’t survive long if they treat every glitch as a dead end. What they need is resilience—the ability to adapt, recover, or at least communicate what went wrong. My approach doesn’t require pre-programmed “if X then Y” rules for every possible failure, and it doesn’t require training on every conceivable scenario. Instead, it leverages the robot’s own understanding of how its parts fit together.
Looking Forward
This work opens up a lot of possibilities. For example, integrating it with natural language could let robots explain their debugging process to humans: “I think my LIDAR is broken, so I’m switching to my camera.” In multi-robot systems, one agent’s self-assessment could help the team adapt dynamically.
And ultimately, this is about trust. People are far more likely to trust robots that don’t just fail silently, but that can explain what went wrong and show that they’re doing their best to fix it.