
Christopher Thierauf, Matthias Scheutz. International Conference on Development and Learning (ICDL) 2025.
We solve hard problems by imagining different outcomes in our head. How can robots do the same?
Earlier this month, Matthias Scheutz (Directory of the Tufts HRILab) presented our most recent paper at ICDL 2025.
You can read the full paper here.
Real-Sim-Real
Symbolic task planners are good at planning long tasks, but they fail if important information about the environment is missing. For example, a planner might say “open the cabinet and move the food to the pot,” but if the robot doesn’t know how to open the cabinet (pull, twist, latch, or slide), it cannot proceed.
In earlier work on improving symbolic plans with reinforcement learning (see here), I introduced an object-focused reinforcement learning method where robots learn using objects instead of raw motor signals. This approach makes it easier to connect reinforcement learning with symbolic reasoning. It allows RL to offer new knowledge that a symbolic planner can use.
The new step in this paper is what I call real-sim-real:
- Observe the environment. The robot uses perception (with help from a vision–language model) to construct a rough simulation of the scene.
- Train in the simulation. It explores possible ways to interact with objects, discovering symbolic operators it was missing.
- Return to reality. It tries the candidate actions, learns from the outcome, and updates both its simulation and symbolic knowledge.
Thanks to the object-centric RL approach, the simulation doesn’t actually need to be precise. It just needs to be representative enough that the robot can “imagine” and reason through possible solutions.
VLMs for Assembling Simulations

A key part of this system is the vision–language model (VLM). The VLM connects the robot’s raw view to a structured description. Given a scene image, it uses automated prompts to identify objects and their layout. If these objects match known “object primitives,” we can combine them into bigger objects (for example, a door and a shelf make a cabinet).
The VLM is not always perfect: it can mix up a drawer with a door or miss a connection. But even rough descriptions can start a simulation. When there is confusion, we consider all possible options. Then, the RL agent tries different ways the environment could work and learns which actions are correct.
The VLM gives the robot some possible “starting stories” about its environment. Then, the real-sim-real loop removes the wrong ones as the robot acts and learns.
A Failed Detour: Voxel Worlds
Before choosing this method, I tried using a depth camera to create a voxel map of the area. The goal was to give the robot a 3D view of its surroundings that could be turned into physics objects in a PyBullet setup.
In practice, it didn’t work. The voxel output was too rough and noisy to support reliable interaction or reasoning. Cabinets and handles looked like unclear blobs. This failure showed me that simple, object-based simulation is more useful than a noisy digital twin.
I still believe there is potential in this area. Using a VLM to gather candidate objects simplifies the process, but those objects must already exist. It also needs an RL method that can handle imperfect simulation. If these issues are solved, an end-to-end RL approach seems possible.
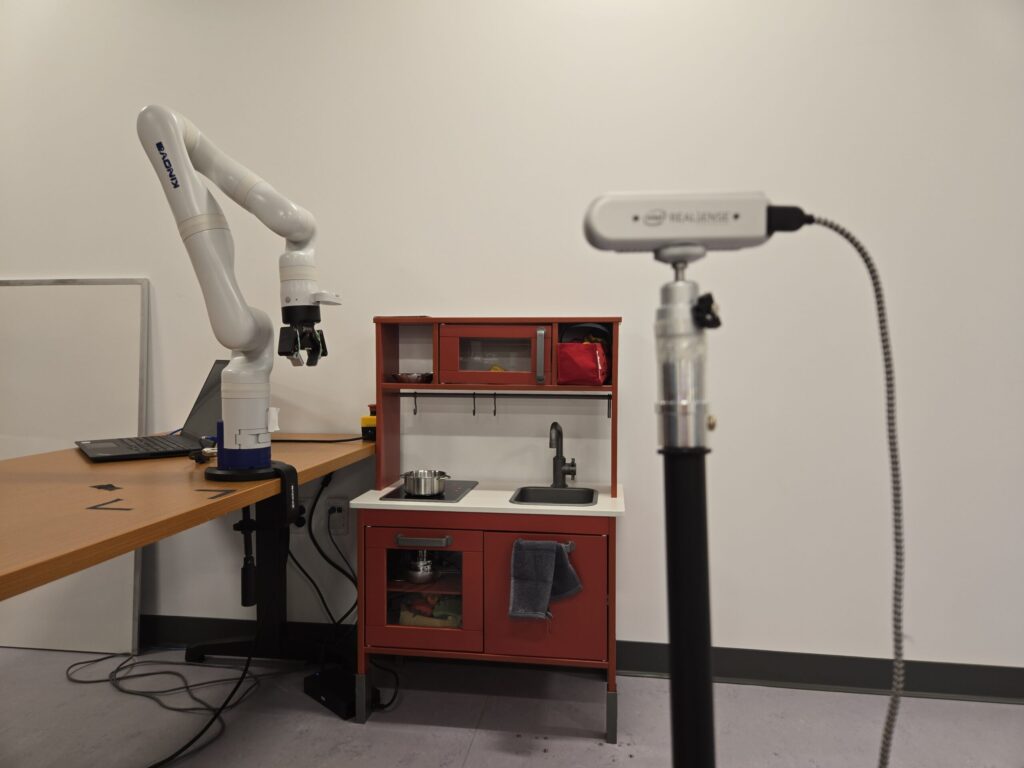
The Kitchen Demo

I tested this with a Kinova arm in a toy kitchen. The task was simple: move food from a cabinet to a pot. But the robot didn’t know how the cabinet worked, so it failed at first. To fix this, it made several simulations.
It gave several options: one simulation needs twisting a handle, another needs pulling. It tried twisting first and failed. Any simulation with twisting is wrong and removed. Then it tried pulling, worked, and completed the task.
Even the failed attempt wasn’t wasted, because it improved the robot’s knowledge.
Takeaways
Using object-first RL with the real–sim–real loop helps robots deal with new situations. Symbolic planners work well when they have the right operators, but if not, reinforcement learning steps in. By seeing simulations as ways to explore instead of exact copies, the robot can imagine options, try them out, and learn.